
Inferencia respecto a la media poblacional
Estimación puntual
Decimos que la estimación de un parámetro es puntual cuando utilizamos un sólo valor del estadístico para aproximar el valor del parámetro.
Ejemplo 1 Un estimador de la media poblacional es la media muestral $$\overline{X}$$ y un estimado es el valor $$\overline{x}=530.5$$ Un estimador de la varianza poblacional es la varianza muestral S² y un estimado es el valor s²=530.
Observe que se utiliza letras minúsculas para el estimado y letras mayúscula para el estimador.
¿Por qué utilizar la media muestral como estimador de la media poblacional? Si tenemos dos muestras, y deseamos compararlas, lo ideal sería tomar todas las posibles observaciones de cada tratamiento y hallar la media (poblacional) de cada uno de ellos. El mejor tratamiento sería el que mostrara mayor o menor media poblacional, según sea el caso. Sin embargo, no es posible aplicar el tratamiento a todo el material experimental debido a la disponibilidad de recursos (materiales, económicos, humanos), por ello, se requiere seleccionar una muestra aleatoria de todo el material posible y con ella determinar una medida que aproxime el valor de la media poblacional (estimador). Esta medida es la media muestral, la cual se dice estadísticamente que es el “mejor” estimador de la media poblacional, debido a que posee propiedades estadísticas deseables como son: insesgamiento, consistencia, de varianza mínima.
Estadísticamente, la media muestral se representa por la letra mayúscula $$\overline{X}$$ y no se refiere al valor obtenido en la muestra del tratamiento sino a todos los valores posibles de todas las muestras que se puedan tomar para ese tratamiento. Así, el valor obtenido para una muestra se representa por $$\overline{x} \quad o \quad \overline{y}_{1.}$$ Este último es solo uno de todos los posibles valores de medias que se pueden obtener, y todos los valores posibles se concentran alrededor del verdadero valor de la media poblacional. Por esto, cuando el tamaño de la muestra se hace más grande, el valor de la media obtenida se acerca mucho más al verdadero valor de la media poblacional y la varianza de las medias es pequeña, con tendencia a cero. A esta última se le conoce como propiedad de consistencia. Si al promediar todos los valores de medias posibles es la verdadera media poblacional, tendremos la propiedad conocida como insesgamiento.
La media muestral $$\overline{X}$$ y la varianza muestral $$S^{2}$$ son estimadores insesgados de $$\mu$$ y $$\sigma^{2}$$ respectivamente ya que $$E[\overline{x}]=\mu$$ y $$E[S^2]=\sigma^2$$ ¿Es posible obtener otra medida que aproxime el valor de la media poblacional? La mediana muestral o el rango medio puede cumplir la propiedad de insesgamiento; pero, estadísticamente se conoce que la media muestral es el estimador insesgado que presenta los valores más cercanos entre sí, por esto se dice que cumple la propiedad de mínima varianza. Con lo anterior podemos decir que, al tomar el valor de la media de una muestra estoy confiando que este valor es “cercano” al verdadero valor de la media poblacional.
DISTRIBUCIÓN MUESTRAL DE LA MEDIA
A la distribución de probabilidad de una estadística se le llama Distribución Muestral. Se puede obtener la distribución muestral de una estadística simulando un muestreo repetitivo de un número fijo n de observaciones de la población dada, se calcula el valor de la estadística, cada vez que se selecciona al azar una muestra de la población y se repite el proceso de muestreo.
Si se repite el proceso un gran número de veces, la distribución de frecuencias relativas de los valores calculados de la estadística, proporcionará una buena aproximación de su distribución muestral. ¿Cómo se distribuyen los valores posibles de medias muestrales? Si se obtienen todas las muestras aleatorias posibles de n observaciones, extraídas con reposición de una población con media μ y desviación estándar σ la distribución muestral (distribución de probabilidad) de $$\overline{X}$$ tendrá una media igual a μ (la misma de la población muestreada) y una desviación estándar igual a $$\sigma/\sqrt{n}$$ o muy conocida como error estándar de la media o error típico de la media. Este valor es muy importante, lo veremos más adelante.
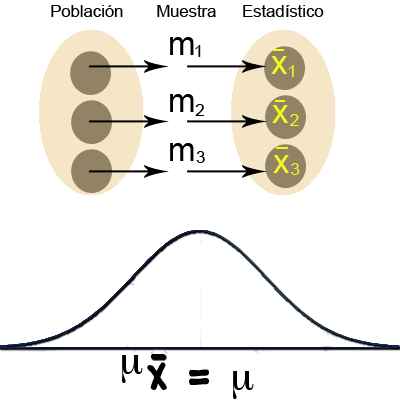
Media de las muestras: $$\mu _ \overline{X}$$
Varianza de las muestras: $$\sigma^2 _ \overline{X}$$
Media del estadístico: $$\mu _ \overline{X}$$
Varianza del estadístico: $$\frac{\sigma^2 _ \overline{X}}{n}$$
Desviación estándar del estadístico (Error estándar): $$\frac{\sigma _ \overline{X}}{\sqrt n}$$
Estimación por intervalo
Puesto que el estadístico muestral $$(\overline{X})$$ varía de una muestra a otra (es decir, depende de los elementos seleccionados en la muestra), se necesita contar con una estimación más precisa de la característica real de la población. Para lograr esto es necesario desarrollar una estimación por intervalo de dicha característica a través de un intervalo estimador, el cual es un intervalo aleatorio cuyos puntos extremos $$L_{1}$ y $L_{2}$$ son estadísticos. Esto se utiliza para determinar un intervalo numérico a partir de una muestra. Se espera que el intervalo numérico obtenido contenga el parámetro de la población que está siendo estimado. El intervalo a elaborar tendrá una confianza específica o probabilidad de estimar correctamente el valor real del parámetro poblacional. Un intervalo de confianza de $\mu$ es un intervalo $$(L_1, L_2)$$ que incluye la media con un grado de certidumbre establecido.
Por ejemplo, un intervalo de confianza del 95% es un intervalo tal que:
$$P[L_1 < \mu < L_2] = 0.95$$
Un intervalo de confianza del 95% para μ significa que cuando se utiliza en un muestreo repetido de la población, el 95% de los intervalos resultantes deberán contener a μ por azar el 5% no incluirá la verdadera media de la población. El grado de confianza deseado es controlado por el investigador.
Para construir un intervalo de confianza de μ se consideran dos casos:
-
- Cuando se conoce la varianza de la población.
- Cuando se desconoce la varianza de la población.
Estimación por intervalo de la media cuando la varianza es conocida
Se conoce que si tenemos una muestra aleatoria $$(\overline{X_1})$$ $$(\overline{X_2})…$ $ $$…(\overline{X_n})$$ de tamaño n de una distribución normal con media μ y varianza σ² entonces
$$\frac{\overline{X} – \mu}{\frac{\sigma}{\sqrt n}}$$
sigue una distribución normal estándar o tipificada. Esta variable aleatoria puede utilizarce para determinar la fórmula general para un intervalo de confianza de $\mu$
Ejemplo
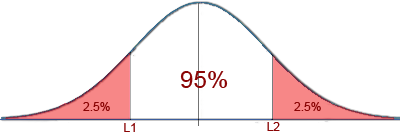
Si queremos construir un intervalo de confianza para $\mu$ del 95%, debemos hallar estadísticos $$L_{1}$$ y $$L_{2}$$ tal que $$P[L_1 < \mu < L_2] = 0.95$$ tal que
Recordemos que
$$Z= \frac {\overline{X} – \mu}{\frac{\sigma}{\sqrt n}} \simeq N(0,1)$$
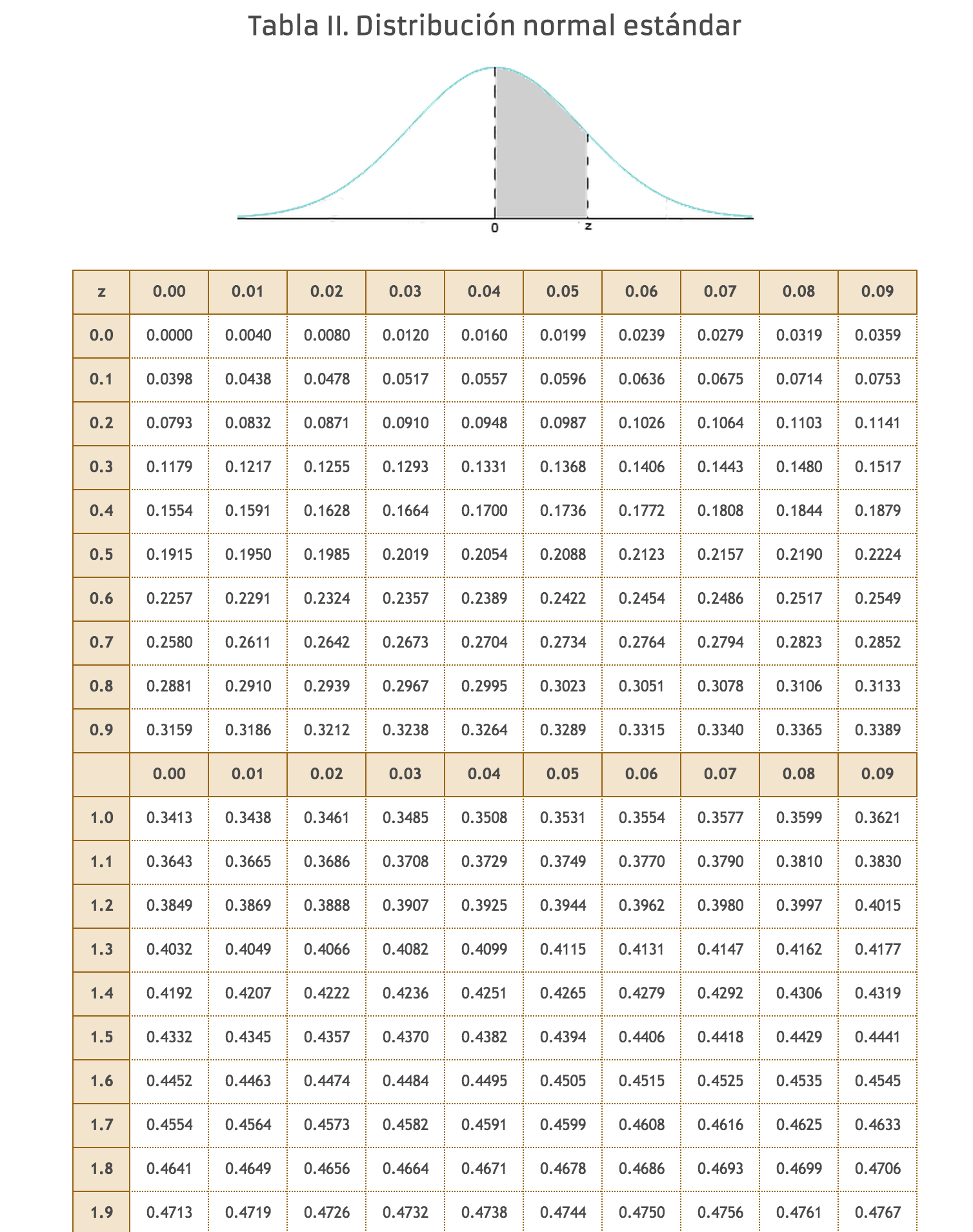
debemos hallar el valor de $$L_1$ y $L_2$$ en la tabla de la distribución normal tal que la probabilildad sea del 95%. Utilizando la tabla 2 vemos que estamos buscando el valor de z tal que la probabilidad sea igual a 0.475 (recuerda qué área proporciona la tabla 2, que la curva es simétrica y que el área total es 1). En la tabla localizamos el valor: 1.96
es decir
$$P[-1.96 \le Z \le 1.96] = 0.95$$
entonces
$$P[-1.96 \le \frac{\overline{X} – \mu}{\frac{\sigma}{\sqrt n}} \le 1.96] = 0.95$$
despejando $$\mu$$
$$\overline{x} -1.96 \frac{\sigma}{\sqrt n} \le \mu \le \overline{x} + 1.96\frac{\sigma}{\sqrt n} $$
por lo que el intervalo para la media poblacional (95%) para la media poblacional será:
$$( \overline{x} -1.96 \frac{\sigma}{\sqrt n}, \quad \overline{x} + 1.96\frac{\sigma}{\sqrt n} ) $$
en términos generales:
$$ \overline{x} \pm z \frac{\sigma}{\sqrt n} $$
donde z es el valor que corresponde a un área del $$\left ( 1 – \frac{\sigma}{2} \right ) $$ en la tabla z acumulada.
Se debe tener en cuenta que se consideró que la variable aleatoria $$\overline{x}$$ se distribuía normal . Si no se satisface esta condición, entonces pueden emplearse los límites de confianza mientras el tamaño de la muestra no sea demasiado pequeña. Estudios experimentales han demostrado que, para muestras tan pequeñas como 25, los límites de confianza son generalmente satisfactorios, a pesar del hecho de ser aproximados. Ello se debe a un importante teorema, conocido como el terorema del límite central:
Teorema del Límite Central
Si se seleccionan muestras aleatorias de $$n$$ observaciones de una población con media $$\mu$$ y desviación estándar $$\sigma$$ finita, entonces, cuando $$n$$ es “grande” la distribución de muestreo de la media muestral $$\overline{X}$$ tendrá aproximadamente una distribución normal con media $$\mu$$ y desviación estándar $$\sigma/\sqrt{n}$$ . Además la variable aleatoria
$$\frac{\overline{X} – \mu}{\frac{\sigma}{\sqrt n}}$$
es aproximadamente normal estándar.
Lo anterior implica que mientras que el tamaño de la muestra no sea demasiado pequeño, $$\overline{X}$$ tiene una distribución aproximadamente normal independientemente de la forma de la distribución de la que se obtenido la muestra.
Estimación por intervalo de la media cuando la varianza es desconocida
En la mayor parte de los casos cuando se realiza un estudio estadístico por primera vez, no hay forma de conocer previamente cuál es la media o la varianza de la población. Para obtener el intervalo estimador se para $$\mu$$ bajo estas condiciones se debe tener en cuenta que no es posible utilizar la variable aleatoria $$\frac{\overline{X} – \mu}{\frac{\sigma}{\sqrt n}}$$ ya que el valor de $$\sigma$$ no es conocido, por ello debe ser estimado y además la distribución de probabilidad no es normal estándar (¿ya adivinaste qué distribución usaremos?).
Un buen estimador de $$\sigma$$ es la desviación muestral $$s$$ a pesar de que no es un estimador insesgado de $$\sigma$$. Al reemplazar en la expresión anterior la desviación poblacional por $$s$$ entonces se conoce teóricamente que la distribución de probabilidad de la variable aleatoria
$$\frac{\overline{X} – \mu}{\frac{s}{\sqrt n}}$$
es t de Student.
Ya conocemos la t de student, por lo que solo resaltaremos algunas características obvias:
-
- Hay un número infinito de variables aleatorias $$t$$, cada una identificada por un parámetro $$n$$, llamado grados de libertad, el cual es siempre un entero positivo.
- Cada variable aleatoria $$t$$ es continua.
- El gráfico de la densidad de cada variable aleatoria $$t_n$$ es una curva simétrica en forma da campana centrada en cero.
- La media y la varianza de una variable aleatoria $$t_n$$ son respectivamente: $$E[t_n]=n$$ y $$Var[t_n]= \frac{n}{n-2}$$ con n > 2
- Cuando el número de grados de libertad crece, la curva de densidad se aproxima a la de una distribución normal.
El valor del estimador, de forma análoga al caso con varianza conocida, pero utilizando la variable $$\frac{\overline{X} – \mu}{\frac{s}{\sqrt n}}$$ es
$$ \overline{x} \pm t_{\alpha/2} \frac{s}{\sqrt n} $$
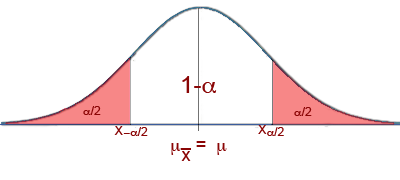
Antes de pasar a los ejemplos, generalicemos lo visto mediante un gráfico
-
-
- $$\alpha$$ se denomina nivel de significancia (o nivel de riesgo) y es una probabilidad. La probabilidad de equivocarse al afirmar que la media está dentro del intervalo.
- 1 – $$\alpha$$ es el nivel de confianza. En este caso, es el porcentaje de casos donde el parámetro poblacional está dentro del intervalo.
Al calcular un intervalo de confianza al 95%, quiere decir que el 95% de las veces que repitamos el proceso de muestreo y calculemos el estadístico, el valor del parámetro poblacional estará dentro de tal intervalo.
-
Ejemplos
Se toma el peso en gramos del contenido de 16 cajas de cereal, con el propósito de verificar el proceso de llenado: 506, 508, 499, 503, 504, 510, 497, 512, 514, 505, 493, 496, 506, 502, 509, 496. Si el peso de cada caja es una variable aleatoria normal con una desviación estándar de 5g, obtener los intervalos de confianza del 90, 95 y 99% para la media de llenado de este proceso.
Para calcular el intervalo con un coeficiente de confianza del 90%, $$\alpha$$=0.1. $$\frac{\alpha}{2}$$=0.0.5. El valor de $$Z_0.95$$ en la tabla de la distribución normal I está entre 1.64 y 1.65 (0.9495 y 0.9505). Podemos tomar el valor menor o sacar un promedio. En este caso, tomaremos un promedio y el valor de $$Z_0.95=1.645$$. La media de los datos muestrales es$$ \overline{x} =503.75g$$. Entonces un intervalo de confianza del 90% para la media del proceso de llenado es
$$ \overline{x} \pm z \frac{\sigma}{\sqrt n} $$
$$503.75 \pm 1.645 \frac{5}{\sqrt 16} $$
o de 501.69 a 505.81. El resto de los intervalos se calculan de la misma forma. Te recomiendo que hagas el procedimiento y compares tus resultados con la siguiente tabla:
| Confianza | Z1 – α/2 | Límite inferior | Límite superior |
| 90% | 1.645 | 501.69 | 505.81 |
| 95% | 1.96 | 501.30 | 506.20 |
| 99% | 2.575 | 500.53 | 506.97 |
En un análisis de control de calidad se midió el tiempo de combustión residual en segundos de 20 especímenes tratados con un nuevo producto de ropa de dormir para niños: 9.85, 9.93, 9.75, 9.77, 9.67, 9.87, 9.67, 9.94, 9.85, 9.75, 9.83, 9.92, 9.74, 9.99, 9.88, 9.95, 9.95, 9.93, 9.92, 9.89. Suponiendo que el tiempo de combustión residual sigue una distribución normal, encontremos el intervalo de confianza del 95% para el tiempo de combustión residual promedio.
Dado que no conocemos la varianza poblaciónal y n < 30, podemos utilizar la distribución t para el cálculo del intervalo. Lo primero será calcular la media y la desviación estándar muestral:
$$ \overline{x} =9.85 $$
$$s = 0.096 $$
$$n=20$$
Grados de libertad= 19
$$\alpha=0.05$$
$$t_{1-0.05/2}=2.05$$
Aplicando la fórmula correspondiente:
$$ \overline{x} \pm t_{\alpha/2} \frac{s}{\sqrt n} $$
$$ 9.85 \pm t_{2.05} \frac{0.096}{\sqrt 20} $$
$$ 9.85 \pm 0.044 $$
El intervalo sería 9.808 – 9.897