
Análisis de la varianza
Análisis de la varianza
El análisis de la varianza (o Anova: Analysis of variance) es un método utilizado para comparar dos o más medias. Cuando se quieren comparar más de dos medias es incorrecto utilizar repetidamente el contraste basado en la t de Student debido a que las dos muestras provienen de la misma población, por lo tanto, cuando se hayan realizado todas las comparaciones, la hipótesis es que todas las muestras provienen de la misma población y, sin embargo, para cada comparación, la estimación de la varianza necesaria para el contraste es distinta, pues se ha hecho en base a muestras distintas.
El método que resuelve este problema es el anova, aunque es algo más que esto: es un método que permite comparar varias medias en diversas situaciones; muy ligado, por tanto, al diseño de experimentos y, de alguna manera, es la base del análisis multivariado.
Bases del análisis de la varianza
Supónganse k muestras aleatorias independientes, de tamaño n, extraídas de una única población normal. A partir de ellas existen dos maneras independientes de estimar la varianza de la población s2
-
- Una llamada varianza dentro de los grupos (ya que sólo contribuye a ella la varianza dentro de las muestras), o varianza de error, o cuadrados medios del error, y habitualmente representada por MSE (Mean Square Error) o MSW (Mean Square Within) que se calcula como la media de las k varianzas muestrales (cada varianza muestral es un estimador centrado de s2 y la media de k estimadores centrados es también un estimador centrado y más eficiente que todos ellos). MSE es un cociente: al numerador se le llama suma de cuadrados del error y se representa por SSE y al denominador grados de libertad por ser los términos independientes de la suma de cuadrados.
- Otra llamada varianza entre grupos (sólo contribuye a ella la varianza entre las distintas muestras), o varianza de los tratamientos, o cuadrados medios de los tratamientos y representada por MSA o MSB (Mean Square Between). Se calcula a partir de la varianza de las medias muestrales y es también un cociente; al numerador se le llama suma de cuadrados de los tratamientos (se le representa por SSA) y al denominador (k-1) grados de libertad.
MSA y MSE, estiman la varianza poblacional en la hipótesis de que las k muestras provengan de la misma población. La distribución muestral del cociente de dos estimaciones independientes de la varianza de una población normal es una F con los grados de libertad correspondientes al numerador y denominador respectivamente, por lo tanto se puede contrastar dicha hipótesis usando esa distribución. Si en base a este contraste se rechaza la hipótesis de que MSE y MSA estimen la misma varianza, se puede rechazar la hipótesis de que las k medias provengan de una misma población. Aceptando que las muestras provengan de poblaciones con la misma varianza, este rechazo implica que las medias poblacionales son distintas, de modo que con un único contraste se contrasta la igualdad de k medias.
Existe una tercera manera de estimar la varianza de la población, aunque no es independiente de las anteriores. Si se consideran las kn observaciones como una única muestra, su varianza muestral también es un estimador centrado de s2: Se suele representar por MST, se le denomina varianza total o cuadrados medios totales, es también un cociente y al numerador se le llama suma de cuadrados total y se representa por SST, y el denominador (n -1) grados de libertad.
Los resultados de un anova se suelen representar en una tabla como la siguiente:
| Tabla de Análisis de Varianza | ||||
| Fuente de variación | G. L. | SS | MS | Fc |
| Entre grupos | k – 1 | SSA | $$\frac{SSA} {(k-1)}$$ | $$\frac {MSA} {MSE}$$ |
| Dentro error | n – k | SSE | $$\frac {SSE} {(n-k)}$$ | |
| Total | n -1 | SST | ||
| Notación | |
| GL | Grados de libertad |
| k | Número de muestras aleatorias |
| n | Tamaño de la muestra |
| SS | Suma de cuadrados |
| SSA | Suma de cuadrados de los tratamientos |
| SSE | Suma de cuadrados del error |
| SST | Suma de cuadrados total |
| MS | Cuadrados medios |
| MSA | Cuadrados medios de los tratamientos |
| MSE | Cuadrados medios del error |
| Fc | Valor del estadístico F |
$$SSA=\sum_{k=1}^K n_k (\bar{x}_k – \bar{\bar{x}})^2 $$
$$SSE=\sum_{k=1}^k\sum_{j=1}^{nk} (x_{kj} – \bar{x_k})^2 $$
$$SST=\sum_{k=1}^k\sum_{j=1}^{nk} (x_{kj} – \bar{\bar{x}})^2 $$
F se usa para realizar el contraste de la hipótesis de medias iguales. La región crítica para dicho contraste es $$F_c > F_a(k-1),(n-k))$$
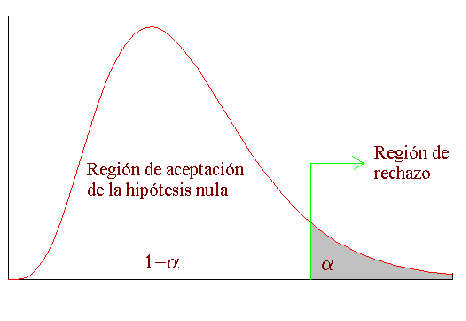
Fc marcaría el lugar donde empieza la zona de rechazo.
Nota que de la tabla de análisis de varianza podemos ver que se cumplen dos propiedades:
-
-
- $$GL_{error} + GL_{tratamientos} = (k – 1) + (n – k) = n – 1= GL_{total}$$
- $$ SST=SSA + SSE $$
-
***
Ejemplo
| Resultados del análisis de plomo en agua de río realizado por 5 laboratorios (k indica el nº de laboratorio) | |||||
| Resultados | Laboratorio A | Laboratorio B | Laboratorio C | Laboratorio D | Laboratorio E |
| 1 2 3 4 5 6 7 |
2.3 4.1 4.9 2.5 3.1 3.7 – |
6.5 4.0 4.2 6.3 4.4 – – |
1.7 2.7 4.1 1.6 4.1 2.8 – |
2.1 3.8 4.8 2.8 4.8 3.7 4.2 |
8.5 5.5 6.1 8.2 – – – |
| Suma Valor medio $$\bar{x}_k$$ nk |
20.6 3.4 6 |
25.4 5.1 5 |
17.0 2.8 6 |
26.2 3.7 7 |
28.3 7.1 4 |
| Media aritmética de todos los resultados $$\bar{\bar{x}}=4.2$$ Número total de resultados N=28 |
|||||
Antes de empezar con los cálculos, observa los valores medios entre los laboratorios. Existen diferencias, que van desde un promedio de 2.8 y hasta 7.1. ¿Estas diferencias son significativas? ¿Se deben a que existen diferencias de plomo entre las muestras? ¿O las diferencias son resultado del azar? El ANOVA resuelve precisamente estas dudas. Recordemos que el objetivo del ANOVA es comparar los diferentes valores para determinar si alguno de ellos difiere significativamente del resto. La hipótesis es clara: Si los resultados proporcionados por los diferentes laboratorios no contienen errores sistemáticos, los valores medios respectivos no diferirán mucho unos de los otros y su dispersión, debida a los errores aleatorios, será comparable a la dispersión presente en cada laboratorio.
En términos que conocemos, esperamos que: μA=μB=μC=μD=μE A esto se se llama hipótesis nula o hipótesis de trabajo y se denomina como H0.
Cualquier diferencia entre algunas de las medias de los diferentes laboratorios nos llevara a rechazar esta hipótesis nula.
Ahora la pregunta es, ¿qué tan diferentes deben ser las medias para considerarlas diferentes? Podemos establecer una zona de probabilidad donde caigan las medias, tal cual lo hemos hecho anteriormente. Esto es, determinar un intervalo de confianza para las medias y estimar si ellas caen en el intervalo. Pero implicaría calcular t’s para cada media y luego buscar la forma de compararlas.
El análisis de varianza utiliza una herramienta estadística más poderosa: La prueba de hipótesis.
Dentro de la inferencia estadística, una prueba de hipótesis (también denominado test de hipótesis, contraste o prueba de significación) es un procedimiento para juzgar si una propiedad que se supone en una población estadística es compatible con lo observado en una muestra de dicha población. Fue iniciada por Ronald Fisher y fundamentada posteriormente por Jerzy Neyman y Karl Pearson. Mediante esta teoría, se aborda el problema estadístico considerando una hipótesis determinada $$H_0$$, y una hipótesis alternativa $$H_1$$ y se intenta dirimir cuál de las dos es la hipótesis verdadera, tras aplicar el problema estadístico a un cierto número de experimentos. Nuestra hipótesis nula:
En H0: μA=μB=μC=μD=μE
Ha: Alguna de las medias es diferente
Está fuertemente asociada a los considerados errores de tipo I y II en estadística, que definen respectivamente, la posibilidad de tomar un suceso falso como verdadero, o uno verdadero como falso.
| Ho es cierta | Ha es cierta | |
| Se escogió Ho | No hay error | Error de tipo II |
| Se escogió Ha | Error de tipo I | No hay error |
Estos errores tienen una probabilidad asociada:
P(escoger Ha | H0 es cierta) = α Error tipo I
P(escoger H0 | Ha es cierta) = β Error tipo II
Es decir, podemos escoger la probabilidad de que el estadístico de prueba que utilicemos nos de un resultado equivocado. Por ejemplo, si el estadístico (la ANOVA) nos indica que la hipótesis nula es correcta, podemos tener un cierto grado de incertidumbre de que estemos equivocados. El error α o error tipo I es el que normalmente definimos en una prueba, dado que H0 es la hipótesis que queremos probar.
Aclaración: Puede haber una cierta confusión en el planteamiento de las hipótesis y cuál es la que queremos probar. Por regla, H0 es la hipótesis que queremos probar, por tanto decimos que es la que queremos rechazar. Es la hipótesis de igualdad. HA es la hipótesis a la que queremos llegar. Por tanto, en una prueba de este tipo queremos aceptar HA dado que HA sea cierta.
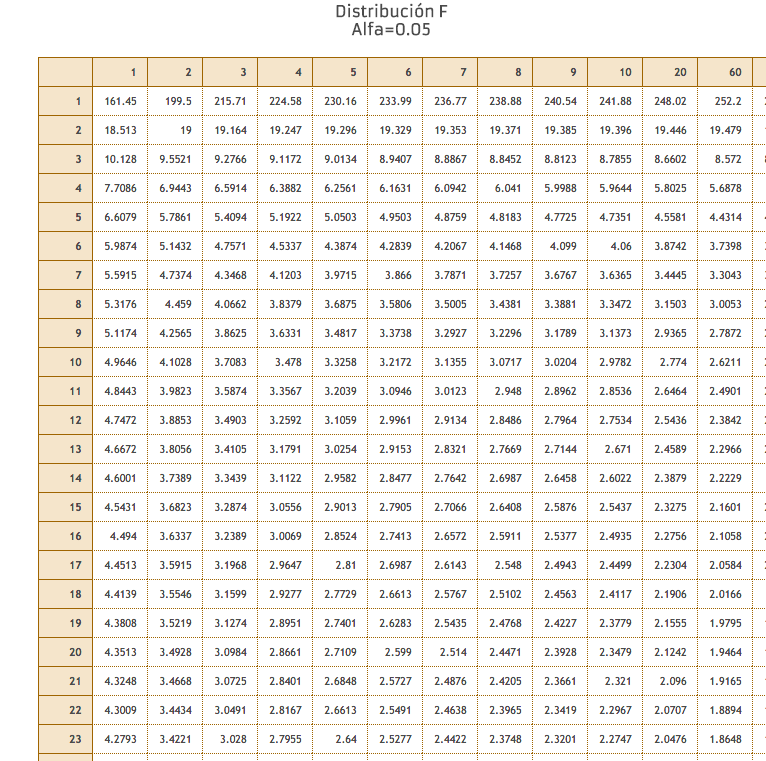
En las tablas de F (tabla V, de la a la g) tenemos diferentes valores de α. De 0.05 a 0.0001 Debería ser evidente que conforme disminuye la probabilidad α, aumenta la probabilidad β. Si α es 0.05 (5%) la probabilidad de β sería 0.95 (95%).
La probabilidad en la tabla F la determinamos de la siguiente forma:
Escogemos un nivel α para la prueba (por ejemplo, 0.05)
Determinamos los grados de libertad en el numerador (k-1)
Determinamos los grados de libertad en el denominador (n-k)
El lugar donde se cruzan, es la probabilidad de la prueba F o región crítica.
En nuestro ejemplo, k-1=4, n-k=23
El valor F es 2.7955
Recordemos que si
$$F_c > F_a(k-1),(n-k))$$
$$F_c > 2.7955$$ entonces rechazamos H0. ¿Recuerdas la gráfica?
Si la Fc > Fa (de tablas: 2.7955) entonces rechazamos H0
Si la Fc < Fa entonces aceptamos H0
Todo esto con una probabilidad de 0.05
Lo que resta ahora, es realizar los cálculos, según la tabla de análisis de varianza:
| Tabla de Análisis de Varianza | ||||
| Fuente de variación | G. L. | SS | MS | Fc |
| Entre grupos | 4 | 53.13 | 13.28 | 10.30 |
| Dentro error | 23 | 29.64 | 1.29 | |
| Total | 27 | 82.77 | ||
$$SSA=\sum_{k=1}^K n_k (\bar{x}_k – \bar{\bar{x}})^2 $$
$$SSE=\sum_{k=1}^k\sum_{j=1}^{nk} (x_{kj} – \bar{x_k})^2 $$
$$SST=\sum_{k=1}^k\sum_{j=1}^{nk} (x_{kj} – \bar{\bar{x}})^2 $$
Por lo que el valor Fa < Fc (α=0.05, 4, 23, 1 cola )=10.30 Rechazamos H0. Alguna de las medias es diferente. O en términos del ejemplo, una de las muestras de laboratorio difiere de las demás (seguramente la de 7.1).
El ANOVA puede utilizarse para comparar entre sí las medias obtenidas de diferentes los resultados, como por ejemplo, diferentes laboratorios, analistas, métodos de análisis, fuentes de información, lugares de muestreo, etcétera.
Sin embargo, el método descrito busca identificar la fuente de variación, descomponiendo la variabilidad total de los datos en dos fuentes de variación: la debida a los laboratorios (entre grupos) y la debida a la precisión dentro de cada laboratorio (dentro error). Matemáticamente, la suma de cuadrados total, SST, puede descomponerse como una suma de dos sumas de los dos cuadrados, como lo describimos anteriormente.
En muestras más complejas, puede haber otras fuentes de variación. Piensa por ejemplo en un ejercicio donde busquemos el ingreso promedio de familias mexicanas. Podemos tomar muestras en un estado en particular y realizar un ANOVA para ver si existe diferencia en cuanto a los métodos de muestreo, por ejemplo. O las muestras pueden ser tomadas en las 16 delegaciones y comparar las 16 medias. Pero podríamos añadir la variable estratos sociales o alguna otra de interés. Entonces el número de medias a examinar sería mayor. Afortunadamente existen ANOVAS para variables múltiples o por estratos o por factores. Estos son los ANOVAS multifactoriales o ANOVAS estratificados, que escapan del temario de este curso.