Mínimos cuadrados ordinarios
Mínimos cuadrados ordinarios
Es una técnica que permite la estimación de los parámetros del modelo lineal
$$Y_i=\alpha X_i + \beta + \epsilon_i$$
minimizando la suma de cuadrados.
A partir del modelo
$$Y_i=\alpha X_i + \beta + \epsilon_i$$
despejamos los errores
$$Y_i – \alpha X_i – \beta = \epsilon_i$$
La suma de cuadrados de εi debería ser 0, por lo que nuestra ecuación queda como
$$\sum_{i=1}^n (Y_i – \hat \alpha X_i – \hat \beta)^2 = \sum_{i=1}^n \hat \epsilon_i^2$$
que representan las distancias en vertical de los datos a la recta de regresión (residuos).
El método de mínimos cuadrados permite encontrar la ecuación de una recta a partir de datos experimentales, es decir obtenemos la pendiente y la ordenada al origen de una recta que mejor se ajuste a dichas mediciones. El método solo sirve para ajustar modelos lineales. En caso de otro tipo de modelos se debe considerar otro método de ajuste.
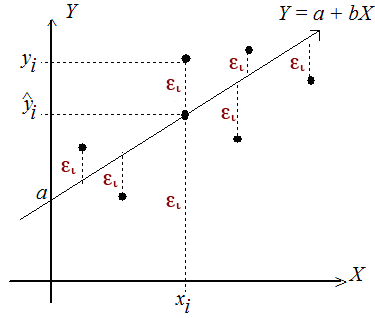
El método de mínimos cuadrados se basa entonces en que la distancia entre el punto experimental (εi en nuestro ejemplo) y la mejor recta posible es mínima. Es decir:
$$\epsilon=y_i-y(x_i)$$ dado que $$\hat y = y(x_i)$$
$$\epsilon=y_i-(bx+a)$$
$$\epsilon^2=[y_i-(bx+a)]^2$$
El método de mínimos cuadrados consistirá en minimizar esta ecuación respecto a los puntos experimentales. El desarrollo de las ecuaciones está fuera del alcance de este curso, por lo que solo nos limitaremos al resultado.
La pendiente de la recta (b) en la ecuación $$\epsilon=y_i-(bx+a)$$ se calcula como
$$b=\frac{n\sum (x_iy_i)- \sum x_i \sum y_i}{n \sum x_i^2 – (\sum x_i)^2}$$
El error del valor de la pendiente se calcularía como
$$S_b=S_y\sqrt{\frac{n}{n \sum x_i^2 – (\sum x_i)^2}}$$
El valor de la ordenada al origen (a) se calcula como
$$a= \frac {\sum x_i^2 \sum y_i – \sum x_i \sum (x_i y_i)}{n \sum x_i^2 – (\sum x_i)^2}$$
El error de la ordenada al origen lo calculamos como
$$S_a=S_y \sqrt{\frac{\sum x_i^2}{n\sum x_i^2 – (\sum x_i)^2}}$$
Por lo que la ecuación de la recta quedaría así:
$$y=(b \pm S_b) x + (a \pm S_a)$$
Recordemos que $$\epsilon^2=[y_i-(bx+a)]^2$$, por lo que Sy es una estimación de estos errores o desviaciones de los puntos.
$$S_y=\sqrt{\frac{\sum \left [ y_i – ( b x_i + a) \right ] ^2}{n-2}}$$
De esta forma, tenemos la ecuación del modelo con un 68% de probabilidad, asumiendo que los resultados se distribuyen normalmente.
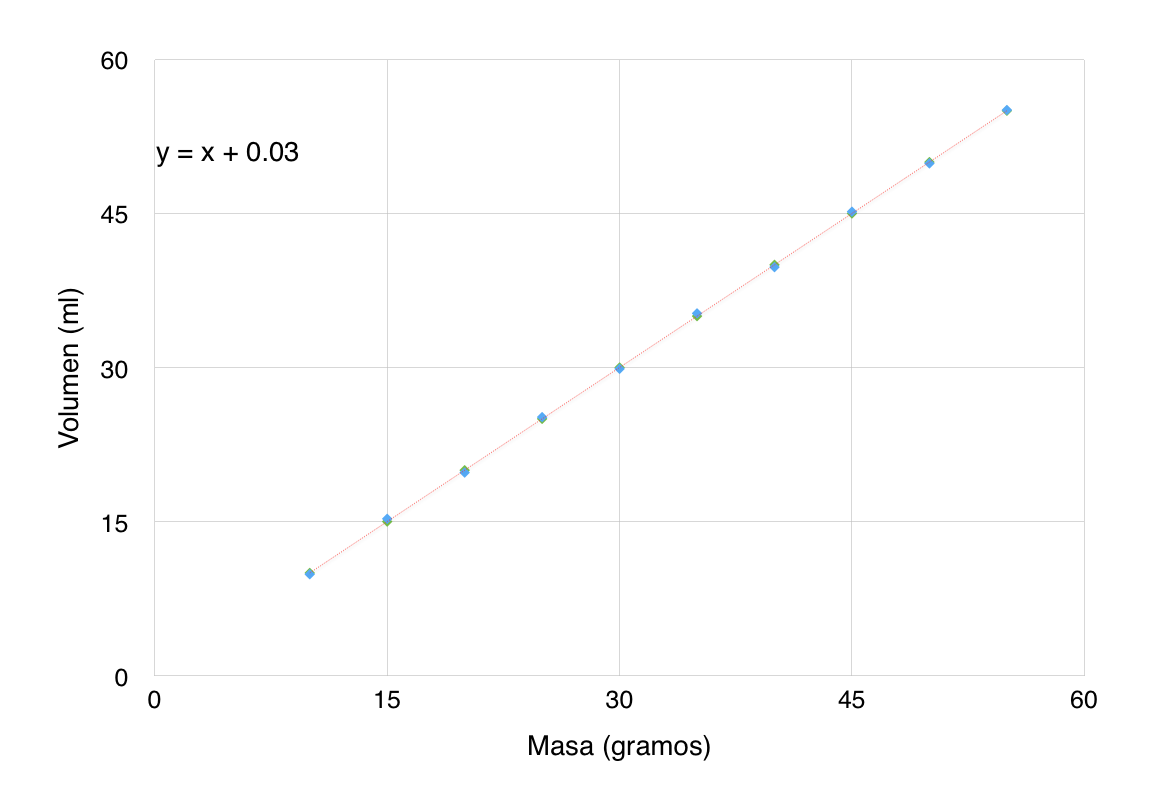
Ejemplo:
Se tienen los siguientes valores de masa y volumen de agua. Encontrar la relación que tienen estas dos variables.
| Observación | Masa (gramos) | Volumen (ml) |
| 1 | 10 | 9.9 |
| 2 | 15 | 15.3 |
| 3 | 20 | 19.8 |
| 4 | 25 | 25.2 |
| 5 | 30 | 29.9 |
| 6 | 35 | 35.3 |
| 7 | 40 | 39.8 |
| 8 | 45 | 45.2 |
| 9 | 50 | 49.9 |
| 10 | 55 | 55.1 |
Al graficar estos datos, observamos cierta tendencia que nos podría indicar que existe una relación entre variables. Por experiencia sabemos que existe y que se llama “densidad” es decir, la relación que existe entre la masa y el volumen.
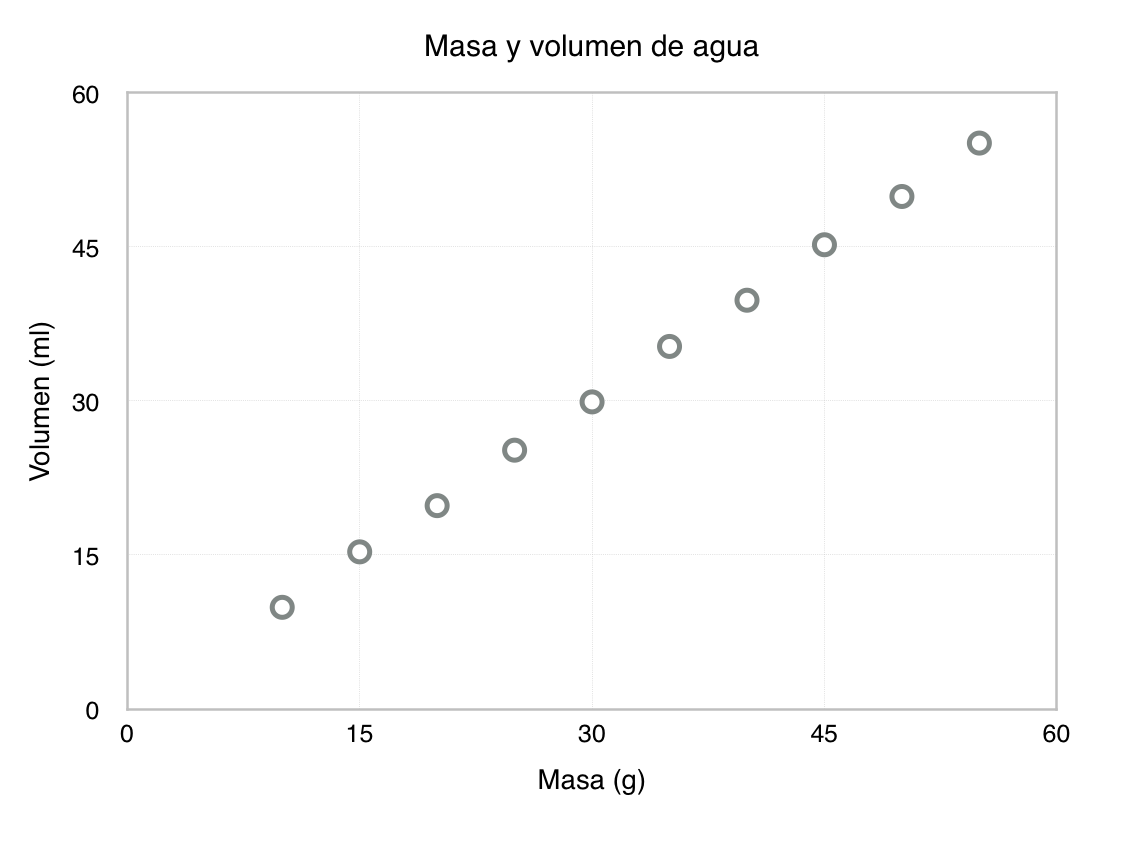
Se pueden hacer los cálculos a mano con una calculadora o se puede usar una hoja de cálculo. Cualquiera que sea el método, sugiero entender muy bien los cálculos antes de usar paquetes estadísticos.
En este caso, utilizaré una hoja de cálculo para hacer las sumatorias y con eso, obtener el valor de la pendiente y la ordenada al origen
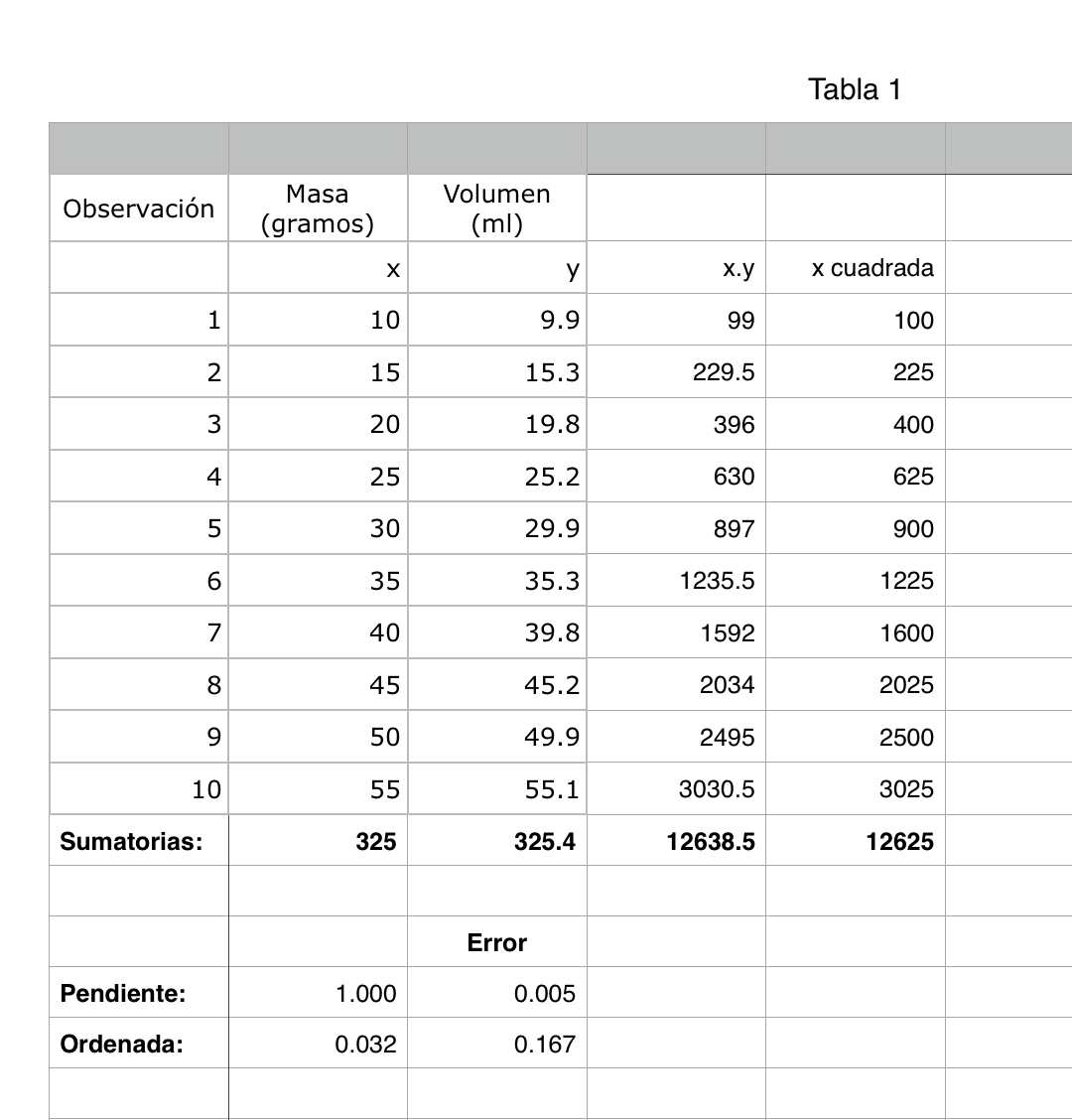
La ecuación será:
$$Volumen =(1.0 \pm 0.005) Masa + (0,03 \pm 0.167)$$
Con esta ecuación podemos obtener los puntos estimados:

Y podemos dibujar una línea de tendencia a los datos originales: