
Distribuciones discretas
Se denomina distribución de variable discreta a aquella cuya función de probabilidad que sólo toma valores positivos en un conjunto de valores de X finito o infinito numerable. A dicha función se le llama función de masa de probabilidad.
En este caso la distribución de probabilidad es la suma de la función de masa, por lo que tenemos entonces que: $$ F(x) = P( X \le x ) = \sum_{k=-\infty}^x f(k) $$
Y, tal como corresponde a la definición de distribución de probabilidad, esta expresión representa la suma de todas las probabilidades desde
$$ -\infty \ hasta \ el \ valor \ x $$
Tipos de distribuciones de variable discreta
-
- La distribución de Bernoulli, que toma valores “1”, con probabilidad p, o “0”, con probabilidad q=1−p.
- La distribución de Rademacher, que toma valores “1” o “-1” con probabilidad 1/2 cada uno.
- La distribución binomial, que describe el número de aciertos en una serie de n experimentos independientes con posibles resultados “sí” o “no” (ensayo de Bernoulli, todos ellos con probabilidad de acierto p y probabilidad de fallo q = 1 − p.
- La distribución de Poisson, que describe el número de eventos de en un cierto intervalo de tiempo y que puede obtenerse como límite de una distribución binominal.
- La distribución beta-binomial, que describe el número de aciertos en una serie de n experimentos independientes con posibles resultados “sí” o “no”, cada uno de ellos con una probabilidad de acierto variable definida por una beta.
- La distribución degenerada en x0, en la que X toma el valor x0 con probabilidad 1. A pesar de que no parece una variable aleatoria, la distribución satisface todos los requisitos para ser considerada como tal.
- La distribución uniforme discreta, en el que todos los resultados posibles forman de un conjunto finito en el que todos son igualmente probables. Esta distribución describe el comportamiento aleatorio de una moneda, un dado o una ruleta de casino equilibrados (sin sesgo).
- La distribución hipergeométrica, que mide la probabilidad de obtener x (0 ≤ x ≤ d) elementos de una determinada clase formada por d elementos pertenecientes a una población de N elementos, tomando una muestra de n elementos de la población sin reemplazo.
- La distribución hipergeométrica no central de Fisher.
- La distribución hipergeométrica no central de Wallenius.
- La ley de Benford, que describe la frecuencia del primer dígito de un conjunto de números en notación decimal.
- La distribución binomial negativa o distribución de Pascal, que describe el número de ensayos de Bernoulli independientes necesarios para conseguir n aciertos, dada una probabilidad individual de éxito p constante.
- La distribución geométrica, que describe el número de intentos necesarios hasta conseguir el primer acierto.
- La distribución beta-binomial negativa, que describe el número de experimentos del tipo “si/no” necesarios para conseguir n aciertos, cuando la probabilidad de éxito de cada uno de los intentos está distribuida de acuerdo con una beta.
- La distribución binomial negativa extendida.
- La distribución de Boltzmann, importante en mecánica estadística, que describe la ocupación de los niveles de energía discretos en un sistema en equilibrio térmico.
Evidentemente solo veremos algunas en este curso, pero es bueno saber que existen muchas más.
Distribución de Bernoulli
En teoría de probabilidad y estadística, la distribución de Bernoulli (o distribución dicotómica), nombrada así por el matemático y científico suizo Jakob Bernoulli, es una distribución de probabilidad discreta, que toma valor 1 para la probabilidad de éxito (p) y valor 0 para la probabilidad de fracaso (q=1-p).
Si X es una variable aleatoria que mide el “número de éxitos”, y se realiza un único experimento con dos posibles resultados (éxito o fracaso), se dice que la variable aleatoria X, se distribuye como una Bernoulli de parámetro p
$$ X \sim Be(p) \, $$
Su función de probabilidad viene definida por:
$$ f(x) = p^x(1-p)^{1-x} \, \qquad \text{ con } \, x = \{0, 1\} \ $$
La fórmula será:
$$ f \left(x;p\right) = \begin{cases}
p \qquad Si \ x = 1, \\
q \qquad si \ x = 0, \\
0 \qquad en \ qualquier \ otro \ caso.
\end{cases} $$
Un experimento al cual se aplica la distribución de Bernoulli se conoce como Ensayo de Bernoulli o simplemente ensayo, y la serie de esos experimentos como ensayos repetidos.
Propiedades
Esperanza matemática:
$$ E\left[X\right] = p = \mu $$
Varianza:
$$ var\left[X\right] = p \left(1 – p\right) = p q $$
Ejemplo
“Lanzar una moneda, probabilidad de conseguir que salga sol”. Se trata de un solo experimento, con dos resultados posibles: el éxito (p) se considerará sacar sol. Valdrá 0.5. El fracaso (q) que saliera águila, que vale (1 – p) = 1 – 0.5 = 0.5.
La variable aleatoria X medirá “número de soles que salen en un lanzamiento”, y sólo existirán dos resultados posibles: 0 (ningún sol, es decir, salir águila) y 1 (un sol). Por tanto, la v.a. X se distribuirá como una Bernoulli, ya que cumple todos los requisitos.
$$ X \sim Be(0.5) $$
$$ P(X = 0) = f(0) = 0.5^0 0.5^1 = 0.5 $$
$$ P(X = 1) = f(1) = 0.5^1 0.5^0 = 0.5 $$
Las características de la distribución son:
-
-
-
- Un solo ensayo
- El ensayo tiene solo dos resultados posibles denominados ¨exito¨ o ¨fracaso¨.
- La probabilidad de exito de cada ensayo, denotada por p, permanece constante.
-
-
Distribución Binomial
Tomemos ahora un ensayo de Bernoulli, tal cual lo definimos anteriormente:
$$ f(x) = p^x(1-p)^{1-x} \, \qquad $$
Un experimento aleatorio que consiste de n ensayos de Bernoulli repetidos tales que
-
-
- Los ensayos son independientes
- Cada ensayo tiene solo dos resultados posibles, denominados “exito” y “fracaso”, y
- La probabilidad de exito en cada ensayo, denotada por p, permanece constante
-
recibe el nombre de experimento binomial.
La variable aleatoria X que es igual al numero de ensayos donde el resultado es un exito, tiene una distribucion binomial con parámetros p y n = 1, 2, ….
La funcion de probabilidad de X es
$$ f(x) = \left ( \frac{n}{x} \right ) p^x(1-p)^{n-x} \, \qquad $$
recordando que
$$\frac{n!}{x!(n-x)!}$$
En la distribución binomial el experimento se repite n veces, de forma independiente, y se trata de calcular la probabilidad de un determinado número de éxitos. Para n = 1, la binomial se convierte, de hecho, en una distribución de Bernoulli.
Las siguientes situaciones son ejemplos de experimentos de esta distribución:
-
-
- Se lanza un dado diez veces y se cuenta el número X de tres obtenidos: entonces X ~ B(10, 1/6)
- Se lanza una moneda dos veces y se cuenta el número X de soles obtenidos: entonces X ~ B(2, 1/2)
-
Existen muchas situaciones en las que se presenta un experimento binomial. Cada uno de los experimentos es independiente de los restantes (la probabilidad del resultado de un experimento no depende del resultado del resto). El resultado de cada experimento ha de admitir sólo dos categorías (a las que se denomina éxito y fracaso). Las probabilidades de ambas posibilidades han de ser constantes en todos los experimentos (se denotan como p y q o p y 1-p). Se designa por X a la variable que mide el número de éxitos que se han producido en los n experimentos.
Cuando se dan estas circunstancias, se dice que la variable X sigue una distribución de probabilidad binomial, y se denota como
$$ X \sim B(n,p) \, $$
Propiedades
Esperanza matemática:
$$ E\left[X\right] = np = \mu $$
Varianza:
$$ var\left[X\right] = np \left(1 – p\right) = np q $$
Ejemplo:
La última novela de un autor ha tenido un gran éxito, hasta el punto de que el 80% de los lectores ya la han leído. Un grupo de 4 amigos son aficionados a la lectura: ¿Cuál es la probabilidad de que en el grupo la hayan leído 2 personas?
n = 4, p = 0.8, p-1= q = 0.2, x=2
$$ f(2) = \left ( \frac{4}{2} \right ) 0.8^2(0.2)^{4-2} = \frac{12} {2} (0.64)* (0.04) = 0.1536$$
Nota la combinación de 4 elementos en 2 grupos. Es el número de formas que los 4 amigos pueden hacer parejas. O dicho de otra forma, es el número de ensayos de Bernoulli.
Y si la pregunta fuera, ¿al menos 2 amigos han leído el libro? Se tendría que calcular la probabilidad para x=2, x=3 y x=4 ya que al menos 2 significa que también cuentan las probabilidades de P(x=2) o P(x=3) o P(x=4). Es decir, se suman las probabilidades. Calcula la probabilidad.
Ahora veamos la Distribución de estos datos. Para ello, tenemos que calcular todos los posibles valores:
|
x |
f(x) |
|
0 |
0.0016 |
|
1 |
0.0256 |
|
2 |
0.1536 |
|
3 |
0.4096 |
|
4 |
0.4096 |
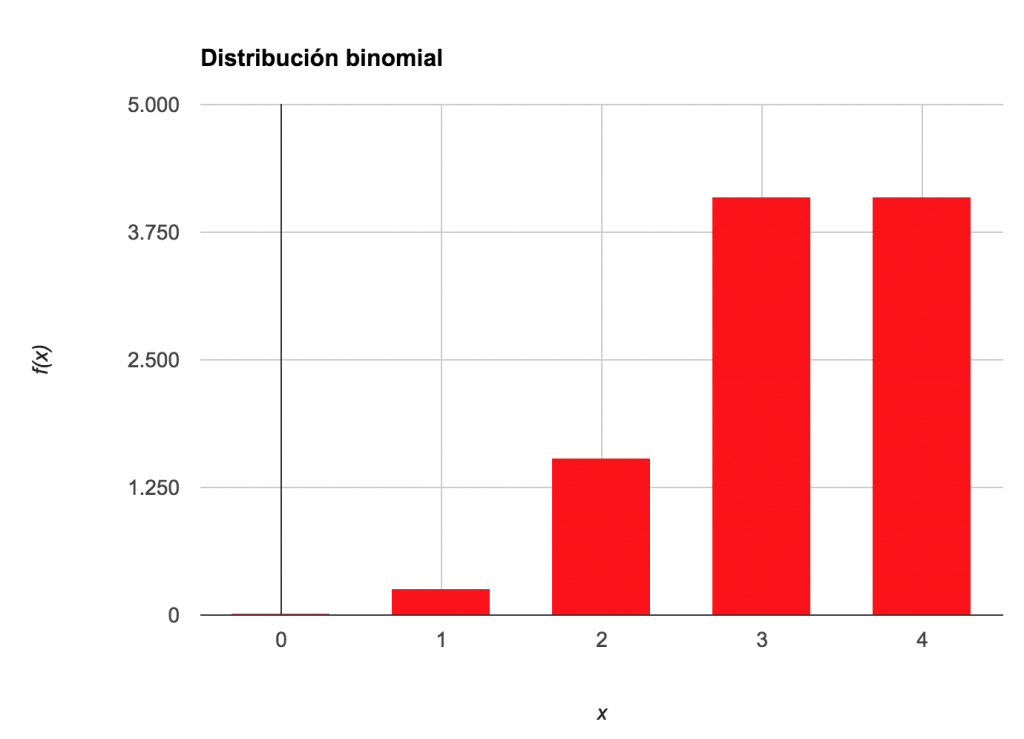
La media de nuestra distribución es 3.2 y la varianza es 0.64. Verifica los resultados.
Distribución de Poisson
La distribución de Poisson es una distribución de probabilidad discreta que expresa la probabilidad de que ocurra un determinado número de eventos durante cierto período de tiempo. Se especializa en la probabilidad de ocurrencia de sucesos con probabilidades muy pequeñas, o sucesos “raros”.
Fue descubierta por Siméon-Denis Poisson en 1838.
Una variable x se distribuye según la distribución de Poisson si
$$ X \sim P(\lambda) \, $$
donde x es el número de ocurrencias del evento o fenómeno (la función nos da la probabilidad de que el evento suceda precisamente x veces). λ es un parámetro positivo que representa el número de veces que se espera que ocurra el fenómeno durante un intervalo dado.
La función de probabilidad está definida como
$$ f(x,\lambda) = \frac{e^ {-\lambda} \lambda^x}{x!} $$
Como vemos, este modelo se caracteriza por un sólo parámetro λ, que debe ser positivo. Esta distribución suele utilizarse para variables del tipo número de individuos por unidad de tiempo, de espacio, etc.
Propiedades del modelo de Poisson
-
-
- Esperanza: E(X) = λ
- Varianza: V(X) = λ
-
Ejemplo
Si el suceso estudiado tiene lugar en promedio 4 veces por minuto y estamos interesados en la probabilidad de que ocurra x veces dentro de un intervalo de 10 minutos, usaremos un modelo de distribución de Poisson con λ = 10×4 = 40. e es la base de los logaritmos naturales (e = 2,71828…)
En este tipo de experimentos los éxitos buscados son expresados por unidad de área, tiempo, pieza, etc, etc,:
-
- # de defectos de una tela por m2
- # de aviones que aterrizan en un aeropuerto por día, hora, minuto, etc, etc.
- # de bacterias por cm2 de cultivo
- # de llamadas telefónicas a un conmutador por hora, minuto, etc, etc.
- # de llegadas de embarcaciones a un puerto por día, mes, etc, etc.
Hay que hacer notar que en esta distribución el número de éxitos que ocurren por unidad de tiempo, área o producto es totalmente al azar y que cada intervalo de tiempo es independiente de otro intervalo dado, así como cada área es independiente de otra área dada y cada producto es independiente de otro producto dado.
Si un banco recibe en promedio 6 cheques sin fondo por día, ¿cuáles son las probabilidades de que reciba,
-
-
- cuatro cheques sin fondo en un día dado,
- 10 cheques sin fondos en cualquiera de dos días consecutivos?
-
Solución:
-
-
- x = variable que nos define el número de cheques sin fondo que llegan al banco en un día cualquiera
x = 0, 1, 2, 3, ….., etc, etc.
λ = 6 cheques sin fondo por día
e = 2.718$$ f(x,\lambda) = \frac{e^{-\lambda} \lambda^{x}}{x!} = \frac{2.718^{-6} 6^4}{4!} = \frac{(0.00248)(1296)}{24}= 0.13392 $$ - x= variable que nos define el número de cheques sin fondo que llegan al banco en dos días consecutivos
x= 0, 1, 2, 3, ……, etc., etc.
λ = 6 x 2 = 12 cheques sin fondo en promedio que llegan al banco en dos días consecutivos
Nota: λ siempre debe de estar en función de x siempre o dicho de otra forma, debe “hablar” de lo mismo que x
e = 2.718
- x = variable que nos define el número de cheques sin fondo que llegan al banco en un día cualquiera
-
$$ f(x,\lambda) = \frac{e^{-\lambda} \lambda^{x}}{x!} = \frac{2.718^{-12} 12^{10}}{10!} = \frac{(6.151×10^{6})(6.1917×10^{10})}{3,628,800}= 0.104953 $$
Distribución Hipergeométrica
Las distribuciones anteriores implican pruebas con dicotomía (como en Bernoulli o binomial) donde se habla de una probabilidad p y una probabilidad 1-p=q, de manera que en cada experimento la probabilidad de obtener cada uno de los posibles resultados se mantiene constante. Esto se logra haciendo experimentos con reemplazo o con una población grande.
Si la población es pequeña y las extracciones no se remplazan las probabilidades no se mantendrán constantes . En ese caso las distribuciones anteriores no nos sirven para la modelar la situación. La distribución hipergeométrica viene a cubrir esta necesidad de modelizar procesos de Bernouilli con probabilidades no constantes (sin reemplazamiento) .
La distribución hipergeométrica es especialmente útil en todos aquellos casos en los que se extraigan muestras o se realizan experimentos repetidos sin devolución del elemento extraído o sin retornar a la situación experimental inicial. Es decir, con cada resultado se ve alterada la probabilidad de obtener en la siguiente prueba uno u otro resultado.
Esta distribución se utiliza en el estudio de muestras pequeñas, de poblaciones pequeñas y en el cálculo de probabilidades de juegos de azar. Además tiene grandes aplicaciones en el control de calidad en otros procesos experimentales en los que no es posible retornar a la situación de partida.
La distribución hipergeométrica puede derivarse de un proceso experimental puro o de Bernouilli con las siguientes características: · El proceso consta de n pruebas , separadas o separables de entre un conjunto de N pruebas posibles. · Cada una de las pruebas puede dar únicamente dos resultados mutuamente excluyentes: A y no A. · En la primera prueba las probabilidades son :P(A)= p y P(A)= q ;con p+q=1
Las probabilidades de obtener un resultado A y de obtener un resultado no A varían en las sucesivas pruebas, dependiendo de los resultados anteriores. Por eso no son constantes.
La ecuación para el cálculo de la distribución es $$ p(x,n) = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} $$
Noten que a pesar de parecer complejo, la ecuación es la definición básica de probabilidad: casos probables entre casos totales.
La combinación $$ {a \choose x} $$ son los eventos que cumplen la condición a $${N-a \choose n-x}$$ son los eventos que cumplen la condición no a y $${N \choose n}$$ es el total de eventos.
Retomando la forma de calcular combinaciones, la ecuación se puede escribir como
$$ p(x,n) = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} $$
Ejemplo
Por error se han colocado 6 tabletas de somnífero en una botella que contiene 9 píldoras de vitamina que son similares en apariencia. Si se seleccionan 3 tabletas aleatoriamente para analizarlas,
¿Cuál es la probabilidad de obtener al menos una tableta de somnífero?
Solución
-
- N = 9+6 =15 total de tabletas
- a = 6 tabletas de somnífero
- n = 3 tabletas seleccionadas
- x = 0, 1, 2, o 3 tabletas de somnífero = variable que nos indica el número de tabletas de somnífero que se puede encontrar al seleccionar las 3 tabletas
Queremos determinar la probabilidad de que de las 3 pastillas, una o más sean de somnífero
p(x=1) o p(x=2) o p(x=3)
veamos la primera probabilidad
$$ p(1,3) = {a \choose x} = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} = \frac{{6 \choose 1}{15-6 \choose 3-1}} {{15 \choose 3}} = \frac{(6) \cdot (36)} {455} = 0.4747 $$
La segunda
$$ p(2,3) = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} = \frac{{6 \choose 2}{15-6 \choose 3-2}} {{15 \choose 3}} = \frac{(15) \cdot (9)} {455} = 0.29677 $$
La tercera
$$ p(3,3) = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} = \frac{{6 \choose 3}{15-6 \choose 3-3}} {{20 \choose 1}} = \frac{(20) \cdot (1)} {455} = 0.0439 $$
La probabilidad de p(x=1) o p(x=2) o p(x=3) es la suma de probabilidades, por lo que la probabilidad de obtener al menos una tableta de somnífero es 0.81537
¿Cuál es la probabilidad de que ninguna pastilla sea de somnífero?
$$ p(0,3) = \frac{{a \choose x}{N-a \choose n-x}} {{N \choose n}} = \frac{{6 \choose 0}{15-6 \choose 3-0}} {{20 \choose 1}} = \frac{(1) \cdot (84)} {455} = 0.18463 $$
Aunque una manera más sencilla sería
$$ p(A’) = 1- p(A)= 1-0.81537= 0.18463 $$
Distribución Uniforme
Es la más simple de todas las distribuciones y en ella la variable aleatoria asume cada uno de los valores con una probabilidad idéntica.
Sea la variable aleatoria X que puede asumir valores x1, x2, x3, …,xn con idéntica probabilidad. Entonces la distribución uniforme discreta viene dada por:
$$ f(x) = p(x=X)=
\begin{cases}
\frac{1}{x} & \mbox{para }x=x_1,x_2,x_3…x_n \\
0 & \mbox{ en otro caso}
\end{cases} $$
El parámetro clave en esta distribución es n=número de valores que asume la variable aleatoria X y que sería un parámetro de conteo.
Por ejemplo cuando se lanza un dado correcto, cada una de las seis caras posibles conforman el espacio muestral:
$$ \Omega = \{1,2,3, 4, 5, 6\}$$
La v.a X: número de puntos en la cara superior del dado tiene una distribución de probabilidad Uniforme discreta, puesto que:
$$ f(x) = p(x=X)=
\begin{cases}
\frac{1}{6} & \mbox{para }x=1,2,3,4,5,6 \\
0 & \mbox{ en otro caso}
\end{cases} $$