
Estimación y predicción
La meta del análisis de regresión es desarrollar un modelo estadístico que se pueda usar para predecir los valores de una variable dependiente o de respuesta basados en los valores de al menos una variable independiente o explicativa.
Limitamos la estimación y predicción a un modelo de regresión lineal simple, que usa una variable numérica independiente para predecir la variable numérica dependiente. Para establecer una relación cuantitativa entre X y Y es necesario disponer de cierta información muestral. Esta información consiste de un conjunto de pares de observaciones de X y Y, donde cada uno de estos pares pertenece a una unidad elemental particular de la muestra.
Por ejemplo, supongamos que el rendimiento de un proceso químico está relacionado con la temperatura de operación, o la experiencia profesional de los trabajadores a sus respectivos sueldos, las estaturas y pesos de personas, la producción agraria y la cantidad de fertilizantes utilizados, etc. Si mediante un modelo matemático es posible describir tal relación, entonces este modelo puede ser usado para propósitos de predicción, optimización o control.
El término variable se puede definir cómo toda aquella característica o cualidad que identifica a una realidad y que se puede medir, controlar y estudiar mediante un proceso de investigación.
La variable independiente es aquella propiedad, cualidad o característica de una realidad, evento o fenómeno, que tiene la capacidad para influir, incidir o afectar a otras variables. Se llama independiente, porque esta variable no depende de otros factores para estar presente en esa realidad en estudio. Algunos ejemplos de variables independientes son; el sexo, la raza, la edad, entre otros. Veamos un ejemplo de hipótesis donde está presente la variable independiente: “Los niños que hacen tres años de educación preescolar, aprenden a leer mas rápido en primer grado.” En este caso la variable independiente es “hacen tres años de educación preescolar.” Porque para que los niños de primer grado aprendan a leer más rápido, depende de que hagan tres años de educación preescolar.
La variable dependiente; es aquella característica, propiedad o cualidad de una realidad o evento que estamos investigando. Es el objeto de estudio, sobre la cual se centra la investigación en general. También la variable independiente es manipulada por el investigador, porque el investigador el puede variar los factores para determinar el comportamiento de la variable. Por ejemplo: “Los niños que hacen tres años de educación preescolar, aprenden a leer más rápido en primer grado.” En este caso la variable dependiente sería “aprenden a leer mas rápido”, pero aprenden a leer más rápido como consecuencia de que “hacen tres año de educación preescolar”.
Ejemplo
En un análisis de control de calidad de papel se cree que la resistencia del mismo está en función del porcentaje de fibra que posee la pulpa con la que se elabora.
-
- Encontrar el modelo que describa esta relación y
- Determinar el porcentaje de fibra que tendrá una hoja de papel con resistencia 200
| Porcentaje de fibra X |
Resistencia Y |
| 4 | 134 |
| 6 | 145 |
| 8 | 142 |
| 10 | 149 |
| 12 | 144 |
| 14 | 160 |
| 16 | 156 |
| 18 | 157 |
| 20 | 168 |
| 22 | 166 |
| 24 | 167 |
| 26 | 171 |
| 28 | 174 |
| 30 | 183 |
Como primer paso, graficaremos los datos para ver a ojo que tipo de relación guardan.
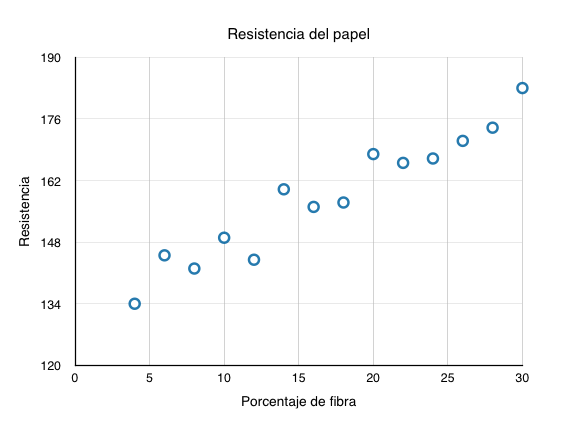
Observamos que puede existir una relación entre las variables. Al menos vemos que cuando aumenta el porcentaje de fibra, aumenta la resistencia.
Ya conocemos el modelo lineal simple y sus hipótesis:
Modelo de Regresión Lineal Simple
Es el modelo más sencillo. Estudia la relación lineal entre la variable de respuesta (Y) y una variable regresora (X), a partir de una muestra (X1, Y1, … , Xn, Yn) que sigue el siguiente modelo lineal:
$$Y_i=\alpha X_i + \beta + \epsilon_i \quad \quad i=1…n$$
donde se verifican las hipótesis del modelo:
-
-
-
- Los errores tienen media cero: $$E[\epsilon_i]=0$$ Consecuentemente, $$E[Y_i]=\alpha X_i + \beta$$
- La varianza del error es constante: $$V(\epsilon_i)=\sigma^2$$ Esta propiedad se conoce como homocedasticidad. Consecuentemente $$V(Y_i)=\sigma^2$$
- La distribución del error es normal N(0, σ). Consecuentemente $$Y_i=N(\alpha X_i+\beta ,\sigma)$$
- Los errores son independientes: $$cov(\epsilon_i, \epsilon_j)=0$$. Consecuentemente las observaciones Yi también lo son.
-
-
En el modelo de regresión lineal simple hay tres parámetros que se deben estimar: los coeficientes de la recta de regresión α y β y la varianza de la distribución normal σ2. Estos parámetros los determinaremos con el método de mínimos cuadrados, que ya vimos, y que en este caso los calcularemos mediante una hoja de cálculo.
Podemos calcular cualquier modelo con hojas de cálculo o con paquetes estadístico. En esta época de tecnología sería tonto hacerlo siempre a mano, pero para fines educativos te recomiendo que entiendas los cálculo y entonces los hagas con algún paquete.
Error de la estimación
Hemos definido, mediante el método de mínimos cuadrados, la metodología para obtener la recta que mejor se ajuste a los datos observados. Y a partir de esta metodología, se obtiene también una estimación de los parámetros que definen la recta (la pendiente b y la ordenada al origen a).
$$\hat y = (b ± S_b) x +(a ± S_a)$$
Una vez obtenida la recta, podemos predecir los datos y estimar qué tan buenos son los datos en comparación con los observados. Definamos entonces los datos observados como (y) y los datos esperados obtenidos del ajuste, como ($$\hat y$$).
Podemos medir entonces la diferencia que existe entre y y $$\hat y$$. Esto se conoce como error en la estimación y se designa como Sxy. El error estándar de la estimación mide la disparidad promedio entre los valores observados y los valores estimados. El cálculo es el siguiente
$$S_{xy} = \sqrt {\frac{\sum (y – \hat y)^2}{n-2}}$$
Debemos entonces calcular los valores de $$\hat y$$ para cada porcentaje de fibra sustituyendo en la ecuación obtenida por mínimos cuadrados.
Utlizaré ahora una hoja de cálculo para obtener la estimación de la recta por mínimos cuadrados, graficaremos los puntos observados y el ajuste de recta y con ello, calcularemos los datos esperados con la recta de mínimos cuadrados
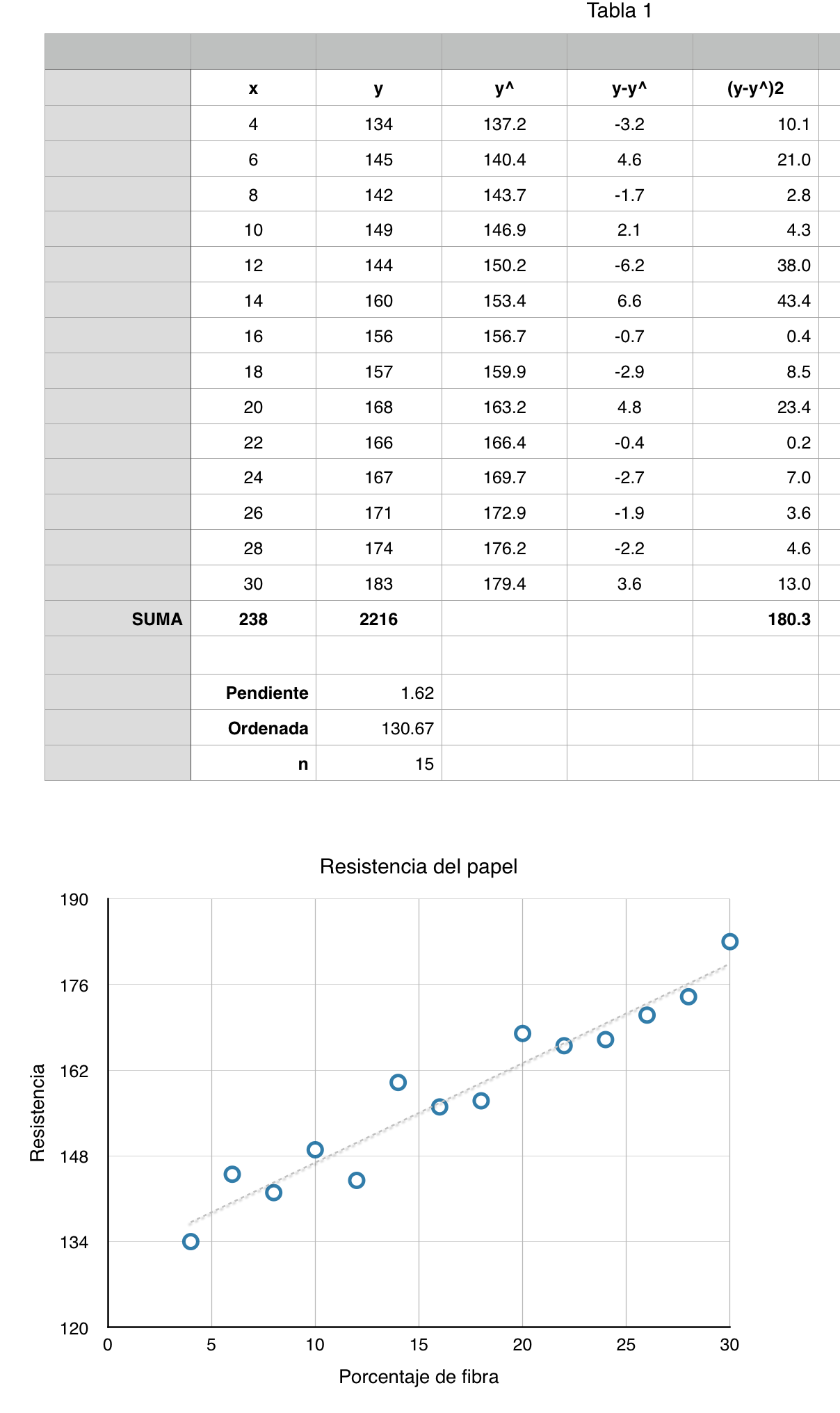
La ecuación de esta recta es
$$\hat y = 1.62 (x) + 130.67 $$
Y el error estándar de la estimación:
$$S_{xy}=\sqrt{\frac{180.93}{13}} = 3.72$$ unidades de resistencia
Sxy es una medida que resume la diferencia entre lo observado y lo estimado, es decir mide la diferencia promedio entre lo observado y lo esperado de acuerdo al modelo. Este valor puede considerarse como un indicador del grado de precisión con la que la ecuación de regresión describe la relación entre las dos variables. El error estándar se ve afectado por las unidades y sus cambios ya que es una medida absoluta pues tiene las mismas unidades de la variable y.
Este valor Sxy resulta útil para ver la variabilidad de los datos estimados. Utilizaremos este dato para sumar y restar a los datos estimados y así ver esta variabilidad gráficamente:
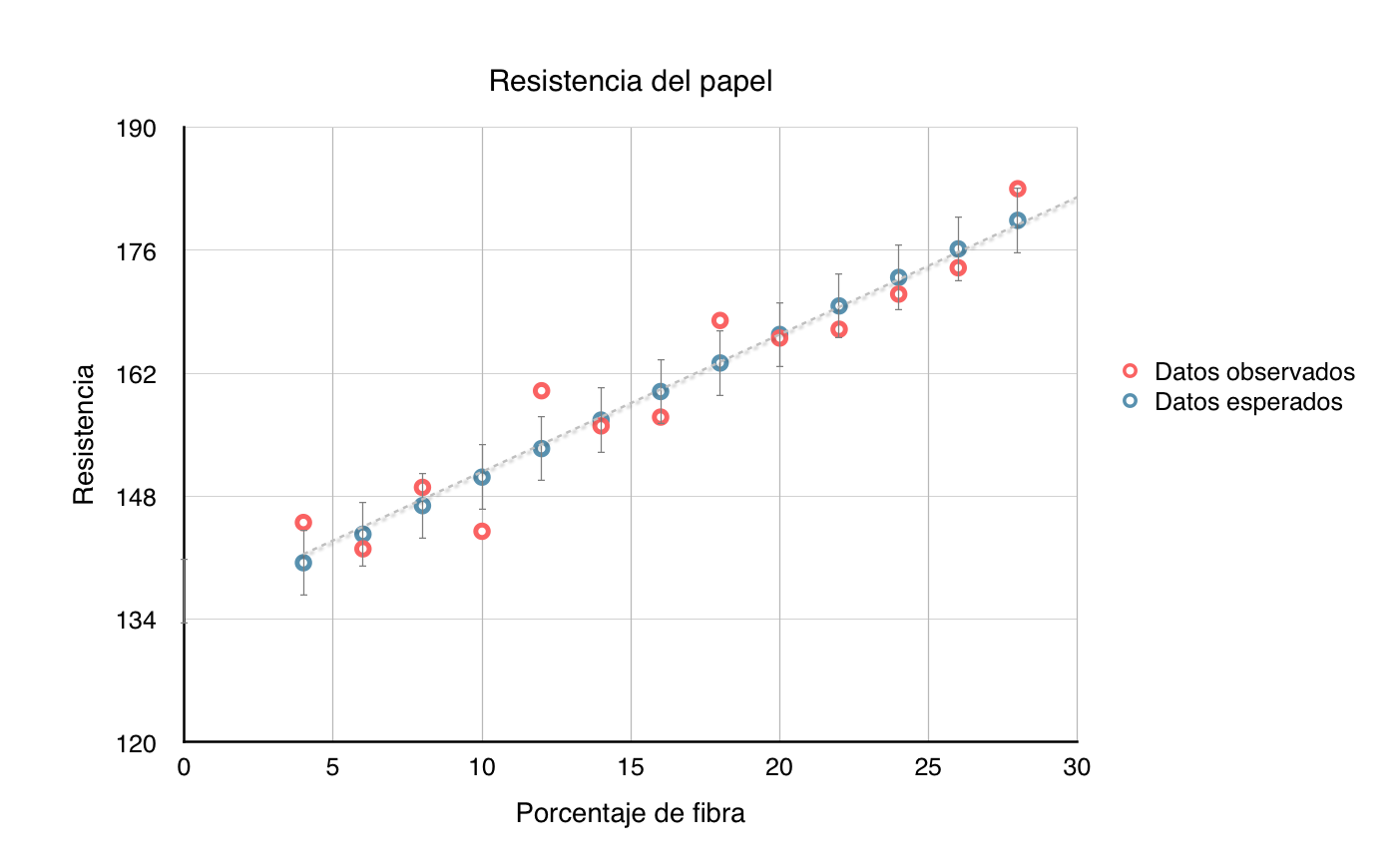
Sin embargo Sxy solo explica una parte de la variabilidad. Trataremos de encontrar un parámetro que explica la mayor parte de la variabilidad.